Character-based Neural Network Translation
Introduction
Traditional methods in language modeling involve making an n-th order Markov assumption and estimating n-gram probabilities via counting. The count-based models are simple to train, but due to data sparsity, the probabilities of rare n-grams can be poorly estimated. Neural Language Models (NLM) address the issue of n-gram data sparsity by utilizing word embeddings [3]. These word embeddings derived from NLMs exhibit the property whereby semantically close words are close in the induced vector space. Even though NLMs outperform count-based n-gram language models [4], they are oblivious to subword information (e.g. morphemes). Embeddings of rare words can thus be poorly estimated, leading to high perplexities (Perplexity is the measure of how well a probability distribution predicts a sample) which is especially problematic in morphologically rich languages.
Character-level Convolutional Neural Network
Let be the vocabulary of characters,
be the dimensionality of character embeddings, and
be the matrix of character embeddings.
Suppose that word
is made up of a sequence of characters
where
is the length of word
Then the character-level representation of
is given by the matrix
where the
th column corresponds to the character embedding for
.
A convolution between and a filter (or kernel)
of width
is applied, after which a bias is added followed by a nonlinearity to obtain a feature map
. The
th element of
is:
= tanh(
H) +b,
where
is the
-to-
-th column of
and
is the Frobenius inner product. Finally, take the max-over-time:
as the feature corresponding to the filter
(when applied to word
. The idea, the authors say, is to capture the most important feature for a given filter. “A filter is essentially picking out a character n-gram, where the size of the n-gram corresponds to the filter width”. Thus the framework uses multiple filters of varying widths to obtain the feature vector for
. So if a total of
filters
are used, then
is the input representation of
.
Highway network
where
is a nonlinearity,
is called the transform gate, and
is called the carry gate. Similar to the memory cells in LSTM networks, highway layers allow for training of deep networks by carrying some dimensions of the input directly to the output.
Essentially the character level CNN applies convolutions on the character embeddings with multiple filters and max pools from these to get a fixed dimensional representation. This is then fed to the highway layer which helps in encoding semantic features which are not dependent on edit distance alone. The output of the highway layer is then fed into an LSTM that predicts the next word.
Convolutional Network based Encoder Model
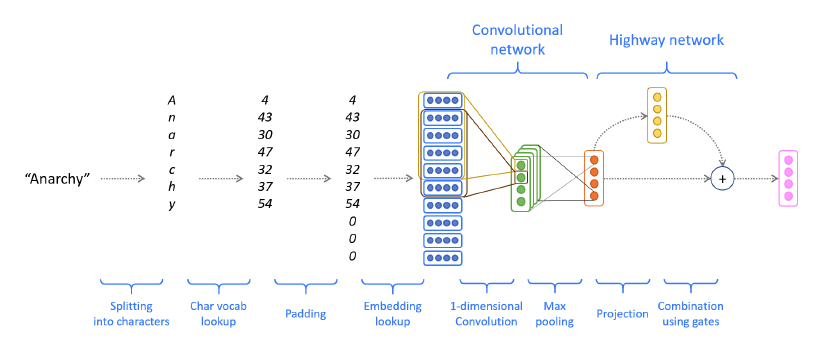
- Convert word to character indices.
- Padding and embedding lookup
- Convolutional network. To combine these character embeddings, we’ll use 1-dimensional convolutions. The convolutional layer has two hyperparameters:4 the kernel size k (also called window size), which dictates the size of the window used to compute features, and the number of filters f(also called number of output features or number of output channels).
- Highway layer and dropout
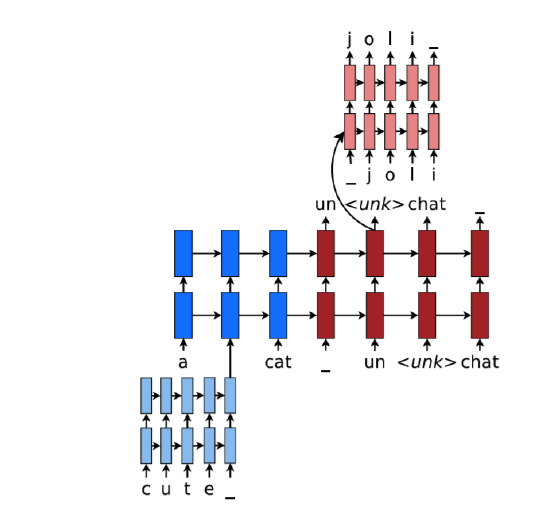
Character-based LSTM decoder for NMT
The LSTM-based character-level decoder to the NMT system, based on Luong & Manning’s paper. The main idea is that when our word-level decoder produces an