Sentiment Analysis Web App - SageMaker Deployment Project
Develop PyTorch Model and Deploy to AWS via SageMaker
- Reference:
Maas, Andrew L., et al. [Learning Word Vectors for Sentiment Analysis](http://ai.stanford.edu/~amaas/data/sentiment/). In _Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies_. Association for Computational Linguistics, 2011.
Project Overview
[Jupyter Notebook - Model and Deployment]
1. Download or otherwise retrieve the data
- IMDB Review DataSet: http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
2. Feature Enginerring for Text Data and Prepare Train/Test DataSet
-
Tokenization
-
Build Word Dictionary To begin with, we need to construct a way to map words that appear in the reviews to integers. Here we fix the size of our vocabulary (including the ‘no word’ and ‘infrequent’ categories) to be 5000 but you may wish to change this to see how it affects the model.
-
Transform and Embedding Transform review into sequence representation, making sure to pad or truncate to a fixed length, which in our case is
500.
3. Upload the processed data to S3
-It is important to note the format of the data that we are saving as we will need to know it when we write the training code. In our case, each row of the dataset has the form label, length, review[500] where review[500] is a sequence of 500 integers representing the words in the review.
- Next, we need to upload the training data to the SageMaker default S3 bucket so that we can provide access to it while training our model.
4. Build and Train PyTorch Model
- AWS SageMaker model comprises three objects
- Model Artifacts
- Training Code
- Inference Code
each of which interact with one another. We develop a PyTorch model for sentiment analysis along with a training script in
trainfolder
- When a PyTorch model is constructed in SageMaker, an entry point must be specified. This is the Python file which will be executed when the model is trained. Inside of the
traindirectory is a file calledtrain.pywhich has been provided and which contains most of the necessary code to train our model.
5. Test the trained model (typically using a batch transform job)
- our model takes input of the form review_length, review[500] where review[500] is a sequence of 500 integers which describe the words present in the review, encoded using word_dict. Fortunately for us, SageMaker provides built-in inference code for models with simple inputs such as this.
- There is one thing that we need to provide, however, and that is a function which loads the saved model. This function must be called model_fn() and takes as its only parameter a path to the directory where the model artifacts are stored. This function must also be present in the python file which we specified as the entry point. In our case the model loading function has been provided and so no changes need to be made.
6. Deploy the trained model
- Once deployed, we can read in the test data and send it off to our deployed model to get some results. Once we collect all of the results we can determine how accurate our model is.
7. Deploy the model for Web App
- When deploying a PyTorch model in SageMaker, you are expected to provide four functions which the SageMaker inference container will use.
model_fn: This function is the same function that we used in the training script and it tells SageMaker how to load our model.input_fn: This function receives the raw serialized input that has been sent to the model’s endpoint and its job is to de-serialize and make the input available for the inference code.output_fn: This function takes the output of the inference code and its job is to serialize this output and return it to the caller of the model’s endpoint.predict_fn: The heart of the inference script, this is where the actual prediction is done and is the function which you will need to complete.
- For the simple website that we are constructing during this project, the input_fn and output_fn methods are relatively straightforward. We only require being able to accept a string as input and we expect to return a single value as output. You might imagine though that in a more complex application the input or output may be image data or some other binary data which would require some effort to serialize.
8. AWS Lambda and API Gateway for Web App
- The AWS Deployment Web Data Flow

The diagram above gives an overview of how the various services will work together.
- On the far right is the model which we trained above and which is deployed using SageMaker. On the far left is our web app that collects a user’s movie review, sends it off and expects a positive or negative sentiment in return.
- In the middle is where some of the magic happens. We will construct a Lambda function, which you can think of as a straightforward Python function that can be executed whenever a specified event occurs. We will give this function permission to send and recieve data from a SageMaker endpoint.
-
Lastly, the method we will use to execute the Lambda function is a new endpoint that we will create using API Gateway. This endpoint will be a url that listens for data to be sent to it. Once it gets some data it will pass that data on to the Lambda function and then return whatever the Lambda function returns. Essentially it will act as an interface that lets our web app communicate with the Lambda function.
- Setup AWS Lambda Function
- This Lambda function will be executed whenever our public API has data sent to it. When it is executed it will receive the data, perform any sort of processing that is required, send the data (the review) to the SageMaker endpoint we’ve created and then return the result.
- Setup API Gateway
#### 9. Sentiment Analysis Web App Examples
Example 1: 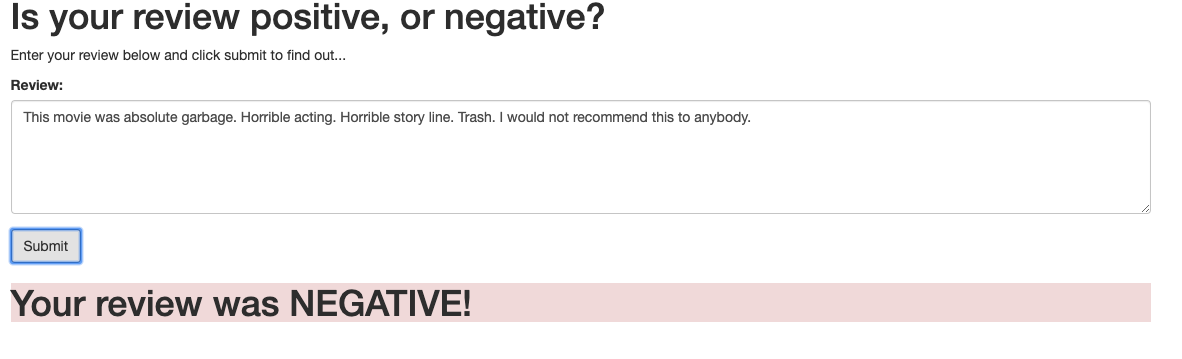
Example 2: 
Delete the endpoint
Remember to always shut down your endpoint if you are no longer using it. You are charged for the length of time that the endpoint is running so if you forget and leave it on you could end up with an unexpectedly large bill.