Twitter Text Mining
Github
Twitter text mining is getting lots of attention in the recent years. We will use the tidy package to analysis text. One way to analyze the sentiment of a text is to consider the text as a combination of its individual words and the sentiment content of the whole text as the sum of the sentiment content of the individual words. We will analysis the Trump and Clinton’s Tweets during 2016 presidential campaign.
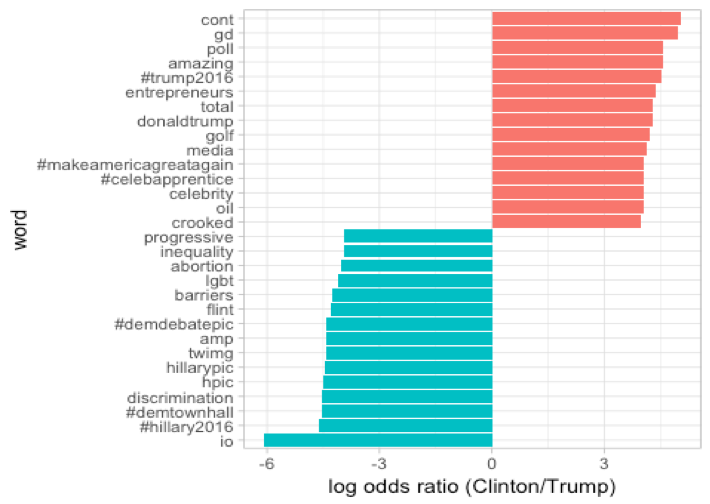
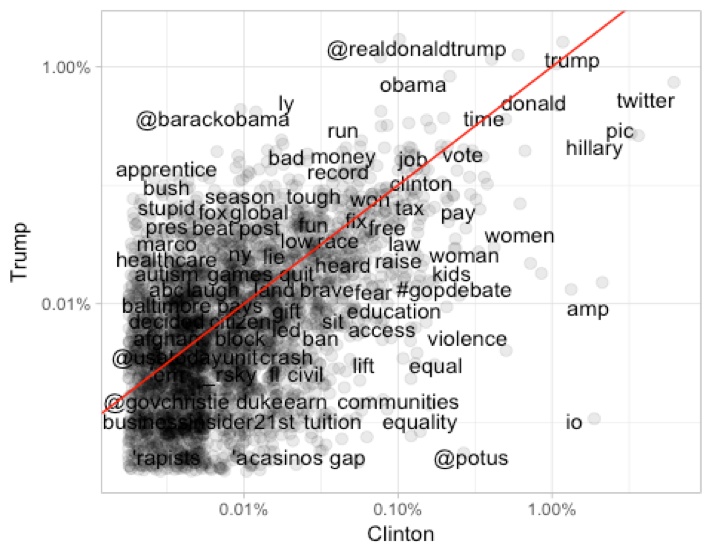
The second part we will give the words frequencies information and plot comparing raw word frequencies over the whole Twitter histories and find which words are more or less likely to come from each person’s account using the log odds ratio.
Data set and Package information
Trump and Clinton’s twitter archives are downloaded from the online twitter archive repertoire. The raw data format is as below.
- Trump Tweets Analysis
Based on the raw data, first we should prepare the tweet data date information, and then we will get the whole picture of Trump’s tweets by years, by pictures and by links.
- Clinton Tweet Analysis
Based on the raw data, first we should prepare the tweet data date information, and then we will get the whole picture of Trump’s tweets by years, by pictures and by links.
- Words Frequencies Analysis
By using unnest_tokens() to make a tidy data frame of all the words in our tweets,
and remove the common English stop words. We will use mutate() line removes links and cleans out some characters that we don’t want.
- Words Ratios Analysis
We count how many times each person uses each word and keep only the words used more than 10 times. After a spread() operation, we can calculate the log odds ratio for each word. We will see the detailed total words for each person.